Hello guys, if you are looking for a Java program to print the word and their count from a given file then you have come to the right place. Earlier, I have shared 100+ Data Strucutre and Algorithms Problems from interviews and in this article, I will show you how to find worlds and their count from a given file in Java. How to find the word and their count from a text file is another frequently asked coding question from Java interviews. The logic to solve this problem is similar to what we have seen in how to find duplicate words in a String, where we iterate through string and store word and their count on a hash table and increment them whenever we encounter the same word.
In the first step, you need to build a word Map by reading the contents of a Text File. This Map should contain words as a key and their count as value. Once you have this Map ready, you can simply sort the Map based upon values.
Btw, If you don't know how to sort a Map on values, see this tutorial first. It will teach you how to sort HashMap on values in Java.
Now getting key and value sorted should be easy, but remember HashMap doesn't maintain order, so you need to use a List to keep the entry in sorted order.
Once you got this list, you can simply loop over the list and print each key and value from the entry. This way, you can also create a table of words and their count in decreasing order. This problem is sometimes also asked to print all words and their count in tabular format.
Now getting key and value sorted should be easy, but remember HashMap doesn't maintain order, so you need to use a List to keep the entry in sorted order.
Once you got this list, you can simply loop over the list and print each key and value from the entry. This way, you can also create a table of words and their count in decreasing order. This problem is sometimes also asked to print all words and their count in tabular format.
By the way, if you are new to Java Programming and not familiar with essential Data Structure and their implementation on Collection Farmwork then I highly recommend you to join a comprehensive Java course like The Complete Java Masterclass by Tim Buchalaka and his team on Udemy. This 80+ hour course is the most comprehensive and up-to-date course to learn Java online.
The most important part of this solution is sorting all entries. Since Map.Entry doesn't implement the Comparable interface, we need to write our own custom Comparator to sort the entries.
If you look at my implementation, I am comparing entries on their values because that's what we want. Many programmers say that why not use the LinkedHashMap class? but remember, the LinkedHashMap class keeps the keys in sorted order, not the values. So you need this special Comparator to compare values and store them in List.
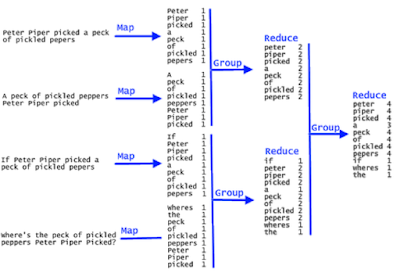
Here is one approach to solving this problem using the map-reduce technique. If you are not familiar with map-reduce and functional programming in Java then I highly recommend you to join Learn Java Functional Programming with Lambdas & Streams course on Udemy. It's a great course to learn essential Functional Programming concepts and methods like map, flatmap, reduce, and filter in Java.
1. Close files and streams once you are through with it, see this tutorial to learn the right way to close the stream. If you are in Java 7, just use the try-with-resource statement.
2. Since the size of the file is not specified, the interviewer may grill you on cases like What happens if the file is large? With a large file, your program will run out of memory and throw java.lang.OutOfMemory: Java Heap space.
One solution for this is to do this task in chunks like first read 20% content, find the maximum repeated word on that, then read the next 20% content, and find repeated maximum by taking the previous maximum into consideration. This way, you don't need to store all words in memory and you can process any arbitrary length file.
3. Always use Generics for type safety. It will ensure that your program is correct at compile time rather than throwing Type related exceptions at runtime.
That's all on how to find repeated words from a file and print their count. You can apply the same technique to find duplicate words in a String. Since now you have a sorted list of words and their count, you can also find the maximum, minimum, or repeated words which has counted more than the specified number.
Other Coding Problems from Interviews You can Practice
How to find the highest repeated word from a File in Java
Here is the Java program to find the duplicate word which has occurred a maximum number of times in a file. You can also print the frequency of words from highest to lowest because you have the Map, which contains the word and their count in sorted order. All you need to do is iterate over each entry of Map and print the keys and values.The most important part of this solution is sorting all entries. Since Map.Entry doesn't implement the Comparable interface, we need to write our own custom Comparator to sort the entries.
If you look at my implementation, I am comparing entries on their values because that's what we want. Many programmers say that why not use the LinkedHashMap class? but remember, the LinkedHashMap class keeps the keys in sorted order, not the values. So you need this special Comparator to compare values and store them in List.
Here is one approach to solving this problem using the map-reduce technique. If you are not familiar with map-reduce and functional programming in Java then I highly recommend you to join Learn Java Functional Programming with Lambdas & Streams course on Udemy. It's a great course to learn essential Functional Programming concepts and methods like map, flatmap, reduce, and filter in Java.
Java Program to Print word and their counts from a File
Here is our complete Java program to find and print the world their count from a given file. It also prints the world with the highest and lowest occurrence characters from the file as asked in given problem.import java.io.BufferedReader; import java.io.DataInputStream; import java.io.FileInputStream; import java.io.FileNotFoundException; import java.io.IOException; import java.io.InputStream; import java.io.InputStreamReader; import java.util.ArrayList; import java.util.Collections; import java.util.Comparator; import java.util.HashMap; import java.util.List; import java.util.Map; import java.util.Map.Entry; import java.util.Set; import java.util.StringTokenizer; import java.util.regex.Pattern; /** * Java program to find count of repeated words in a file. * * @author */ public class Problem { public static void main(String args[]) { Map<String, Integer> wordMap = buildWordMap("C:/temp/words.txt"); List<Entry<String, Integer>> list = sortByValueInDecreasingOrder(wordMap); System.out.println("List of repeated word from file and their count"); for (Map.Entry<String, Integer> entry : list) { if (entry.getValue() > 1) { System.out.println(entry.getKey() + " => " + entry.getValue()); } } } public static Map<String, Integer> buildWordMap(String fileName) { // Using diamond operator for clean code Map<String, Integer> wordMap = new HashMap<>(); // Using try-with-resource statement for automatic resource management try (FileInputStream fis = new FileInputStream(fileName); DataInputStream dis = new DataInputStream(fis); BufferedReader br = new BufferedReader( new InputStreamReader(dis))) { // words are separated by whitespace Pattern pattern = Pattern.compile("\\s+"); String line = null; while ((line = br.readLine()) != null) { // do this if case sensitivity is not required i.e. Java = java line = line.toLowerCase(); String[] words = pattern.split(line); for (String word : words) { if (wordMap.containsKey(word)) { wordMap.put(word, (wordMap.get(word) + 1)); } else { wordMap.put(word, 1); } } } } catch (IOException ioex) { ioex.printStackTrace(); } return wordMap; } public static List<Entry<String, Integer>> sortByValueInDecreasingOrder( Map<String, Integer> wordMap) { Set<Entry<String, Integer>> entries = wordMap.entrySet(); List<Entry<String, Integer>> list = new ArrayList<>(entries); Collections.sort(list, new Comparator<Map.Entry<String, Integer>>() { @Override public int compare(Map.Entry<String, Integer> o1, Map.Entry<String, Integer> o2) { return (o2.getValue()).compareTo(o1.getValue()); } }); return list; } } Output: List of repeated word from file and their count its => 2 of => 2 programming => 2 java => 2 language => 2
Tips for Solving Highest Repeating Characters Count Problem and Things to Remember
If your writing code on interviews make sure they are production quality code, which means you must handle as many errors as possible, you must write unit tests, you must comment on the code and you do proper resource management. Here are a couple of more points to remember:1. Close files and streams once you are through with it, see this tutorial to learn the right way to close the stream. If you are in Java 7, just use the try-with-resource statement.
2. Since the size of the file is not specified, the interviewer may grill you on cases like What happens if the file is large? With a large file, your program will run out of memory and throw java.lang.OutOfMemory: Java Heap space.
One solution for this is to do this task in chunks like first read 20% content, find the maximum repeated word on that, then read the next 20% content, and find repeated maximum by taking the previous maximum into consideration. This way, you don't need to store all words in memory and you can process any arbitrary length file.
3. Always use Generics for type safety. It will ensure that your program is correct at compile time rather than throwing Type related exceptions at runtime.
That's all on how to find repeated words from a file and print their count. You can apply the same technique to find duplicate words in a String. Since now you have a sorted list of words and their count, you can also find the maximum, minimum, or repeated words which has counted more than the specified number.
Other Coding Problems from Interviews You can Practice
- How to find a missing number in a sorted array? (solution)
- How to find the square root of a number in Java? (solution)
- How to check if a given number is prime or not? (solution)
- 10 Free Courses to learn Data Structure and Algorithms (courses)
- How to find the highest occurring word from a text file in Java? (solution)
- 10 Books to learn Data Structure and Algorithms (books)
- How to find if given String is a palindrome in Java? (solution)
- How to reverse a given number in Java? (solution)
- How do you swap two integers without using the temporary variable? (solution)
- Write a program to check if a number is a power of two or not? (solution)
- How do you reverse the word of a sentence in Java? (solution)
- 10 Data Structure and Algorithms course to crack coding interview (courses)
- How to calculate the GCD of two numbers in Java? (solution)
- How to reverse String in Java without using StringBuffer? (solution)
- How to find duplicate characters from a given String? (solution)
- Top 10 Programming problems from Java Interviews? (article)
Nice smile emoticon On java 8 it has done with 4 code line :
ReplyDeleteString data = String.join("", Files.readAllLines(Paths.get("D:\\lab.txt")));
Arrays.asList(data.split(("\\s+"))).stream().collect(Collectors.groupingBy(str->str)).forEach((text,list)->{
System.out.println(String.format("Word: %s - Occur: %d",text,list.size()));});
Nice solution showing the power of streams, but uses temporarily more memory.
DeleteHow does the second point solve your memory problem. Out of memory can occur, if the line is to long or the word map gets too big. For a too long line you need a custom read method. For the a big map you need some external storage solution. If you only store the maximum repeated words (like the top 10, did I understand this correctly?) , you may get wrong results.
DeleteFor an interview, I would also expect that the source follows the "single level of abstraction" principle ( the buildWordMap function).
ReplyDeleteHow to print the line number in which maximum occurances occured , i wanted to show top 5 occurances of the word with the line number
ReplyDeleteHow to print the occurances of the word bases on the line number , i want to print 5 most occurances of the word.
ReplyDeleteLet's see this chain of object creation, file name -> FileInputStream -> DataInputStream -> InputStreamReader -> BufferReader, then finally you can stream content of this file, no wonder Java is such resource hog
ReplyDeleteWhy sort the list at all? The original question asks to "find highest repeating word", you can just navigate the map and find the highest value. This way you are still at O(n) rather than O(n logn) once you resort to sorting.
ReplyDeleteI think you forgot this:
ReplyDeleteline += line + "\n";
before
line = line.toLowerCase();
If the text file has many empty lines, you'll got this output:
=> specific number
If the file is too large which would result in java.lang.OutOfMemoryError, how do you make sure you process only part of the file that would not result in the memory error. In the article it was mentioned as read only 20% process it and move on to next part until you finish processing the entire file. How do you make sure you read only 20% and next time continue from the next 20%. Thanks in Advance
ReplyDelete